weekly reading and tasks
week 1: introduction
In preparation for the workshop, please read in advance:
Reading 1: Dan Cohen and Roy Rosenzweig, Digital History, chapter 'digitising history'
http://chnm.gmu.edu/digitalhistory/digitizing/
- what do they argue are the advantages and disadvantages of digitisation?
- what are the main ways of digitising historic archives?
During the workshop we will be doing the following:
1. review of the major digitisation initiatives;
The British Library have just digitised over a million images in their book collection.They have uploaded them to flickr: http://www.flickr.com/photos/britishlibrary
Read their blog about the project here: http://britishlibrary.typepad.co.uk/digital-scholarship/2013/12/a-million-first-steps.html
2. Brief discussion of keyword searching and the pitfalls of OCR
Discussion of how the 'googlerisation' of information is changing the way we think about and categorise information.
See the handout attached below for an example which we will be working through.
3. Practical review of the free tools and downloads listed on the first page of the reading list.
Task 1. Twitter: https://twitter.com/
Set up your own twitter account, follow @TBC, and look at the twitter feeds of the #twitterstorians the module twitter account follows.
Task 2. Set up your own blog if you haven't done so already,
Blogger: http://www.blogger.com/ Google’s free blog site, available to use with a gmail account etc. Please feel free to use Wordpress instead: http://wordpress.org/
Task 3: Google Advanced Search: http://www.google.co.uk/advanced_search
Make this your ‘home page’, and use it in preference to a normal Google Search.
Other Google services you will want to familiarise yourself with (all available from the header menu on the Google Advanced Search page):
Other sites to evaluate (if time):
Zotero: http://www.zotero.org/
This is the best ‘citation management’ site on the web, and allows you to collect both citations to books and articles, but also websites, as you work online (creating bibliographies you can then export to an essay for example). It works best as a ‘plug-in’ in a browser such as Firefox, but can also be downloaded as a ‘standalone’ application for use with Internet Explorer.
Dropbox: http://www.dropbox.com/
A free file sharing site that allows you to exchange large documents, and back up your local hard disk.
Flickr: http://www.flickr.com/
An image sharing facility – useful for locating the right illustration, and sharing large image files.
For more information on how OCR works and some statistics about its inaccuracy, read Simon Tanner, Trevor Munoz and Pich Hemy Ros, 'Measuring Mass Text Digitization Quality and Usefulness ', D-Lib Magazine, 15: 7/8 (August 2009) http://www.dlib.org/dlib/july09/munoz/07munoz.html
In preparation for the workshop, please read in advance:
Reading 1: Dan Cohen and Roy Rosenzweig, Digital History, chapter 'digitising history'
http://chnm.gmu.edu/digitalhistory/digitizing/
- what do they argue are the advantages and disadvantages of digitisation?
- what are the main ways of digitising historic archives?
During the workshop we will be doing the following:
1. review of the major digitisation initiatives;
The British Library have just digitised over a million images in their book collection.They have uploaded them to flickr: http://www.flickr.com/photos/britishlibrary
Read their blog about the project here: http://britishlibrary.typepad.co.uk/digital-scholarship/2013/12/a-million-first-steps.html
- choose an image from their collection.
- why have they digitised the images? reflecting on what you read in Cohen and Rosenzweig, discuss the advantages and disadvantages.
- compare with other institutional digitisation projects - e.g. British Museum: http://www.britishmuseum.org/research/collection_online/search.aspx
2. Brief discussion of keyword searching and the pitfalls of OCR
Discussion of how the 'googlerisation' of information is changing the way we think about and categorise information.
See the handout attached below for an example which we will be working through.
3. Practical review of the free tools and downloads listed on the first page of the reading list.
Task 1. Twitter: https://twitter.com/
Set up your own twitter account, follow @TBC, and look at the twitter feeds of the #twitterstorians the module twitter account follows.
Task 2. Set up your own blog if you haven't done so already,
Blogger: http://www.blogger.com/ Google’s free blog site, available to use with a gmail account etc. Please feel free to use Wordpress instead: http://wordpress.org/
Task 3: Google Advanced Search: http://www.google.co.uk/advanced_search
Make this your ‘home page’, and use it in preference to a normal Google Search.
Other Google services you will want to familiarise yourself with (all available from the header menu on the Google Advanced Search page):
- Googledocs: A file sharing site that allows you to collaborate on creating word processing documents, spread sheets, etc.
- Google+: Google’s answer to Facebook. I don’t use it much, but we may want to explore it as a social medium for class discussions.
- Google Earth: We will be exploring the opportunities created by Google Earth in the session on mapping; and it would be worthwhile downloading it to your own machine. http://www.google.co.uk/intl/en_uk/earth/index.html
Other sites to evaluate (if time):
Zotero: http://www.zotero.org/
This is the best ‘citation management’ site on the web, and allows you to collect both citations to books and articles, but also websites, as you work online (creating bibliographies you can then export to an essay for example). It works best as a ‘plug-in’ in a browser such as Firefox, but can also be downloaded as a ‘standalone’ application for use with Internet Explorer.
Dropbox: http://www.dropbox.com/
A free file sharing site that allows you to exchange large documents, and back up your local hard disk.
Flickr: http://www.flickr.com/
An image sharing facility – useful for locating the right illustration, and sharing large image files.
For more information on how OCR works and some statistics about its inaccuracy, read Simon Tanner, Trevor Munoz and Pich Hemy Ros, 'Measuring Mass Text Digitization Quality and Usefulness ', D-Lib Magazine, 15: 7/8 (August 2009) http://www.dlib.org/dlib/july09/munoz/07munoz.html
| dhworkshop1notes.pdf |
| dhlecture1slides.pdf |
Week 2: searching
Read the following two pieces in advance in preparation for the workshop:
Reading 1. Ben Schmidt, 'What historians don't know about database design…' blog post, March 2011
http://sappingattention.blogspot.com/2011/03/what-historians-dont-know-about.html
- what does Schmidt argue constrains historians in the ways they can use digital sources?
Reading 2. Cohen & Rosenzweig, Digital History, chapter 'exploring the history web', section, 'archival websites' - http://chnm.gmu.edu/digitalhistory/exploring/3.php
3. If you can get access, please read: Andrew Hobbs, 'The Deleterious Dominance of The Times in Nineteenth-Century Scholarship', Journal of Victorian Culture, 18: 4 (2013)
In the workshop we will be working through the following sites collectively:
- The Old Bailey Online API: http://www.oldbaileyonline.org/obapi/
Search Old Bailey Online – keyword ‘elephant’ and date range (e.g.) January 1692 to January 1739. Find the page source, and the xml.
- The Real Face of White Australia: http://invisibleaustralians.org/faces/
- Comédie-Française Register Project: http://web.mit.edu/hyperstudio/cfr/index.htm/
- Connected Histories: http://www.connectedhistories.org/Default.aspx
- Nines: http://www.nines.org/
- SmartHistory: http://smarthistory.khanacademy.org/
Task 1: Set up your own blog if you haven't done so already,
Blogger: http://www.blogger.com/ Google’s free blog site, available to use with a gmail account etc. Please feel free to use Wordpress instead: http://wordpress.org/
Task 3: on twitter, find the twitter feeds for the above websites, and ask them a question about their databases.
| dhworkshop2notessearching.pdf |
| dhlecture2searching.pptx |
Week 3: Blogs and social media
Reading 1 : Lucy Williams's blog post about her research into Victorian female criminals, and its misuse by the press: http://waywardwomen.wordpress.com/2013/07/01/bloggers-beware/
A revised version of the post is here: http://www.theguardian.com/higher-education-network/blog/2013/dec/04/academic-blogging-newspaper-research-plagiarism - see the comments below it.
- what did Lucy Williams wish to gain from blogging her research?
- to what extent were the press's use of her research 'plagiarism'?
- should Lucy and her peers continue to blog their research?
Reading 2: AND at least one of the following in advance in preparation for the workshop:
a) Guide: 'Blogging for historians' - http://bloggingforhistorians.wordpress.com/guide-to-blogging-main-index/uses-of-blogs-for-historians/
- what are the different types of history blog? what different purposes do they serve?
b) Video: 'The anti-social scholar' - http://bloggingforhistorians.wordpress.com/2013/11/18/the-anti-social-scholar-and-how-not-to-become-one-the-social-scholar/
c) Blog post: 'Social media and the early career historian' by Kate Bradley of the University of Kent: http://antisocialhistorian.wordpress.com/2013/08/03/social-media-and-the-early-career-historian/
d) Article: Melissa Terras , 'The impact of social media on the dissemination of research', Journal of Digital Humanities, 1: 3
http://journalofdigitalhumanities.org/1-3/the-impact-of-social-media-on-the-dissemination-of-research-by-melissa-terras/
You should also have a look at some of the blogs listed below if you need time to read what we will be going through in the workshop.
Some important examples of scholarly blogs (in no particular order). We will work through these in the workshop:
Trevor Owens: http://www.trevorowens.org/
A nice general blog on all things Digital Humanist
Dan Cohen: http://www.dancohen.org/
One of the most important North American blogs, from the director of the Center for History and the New Media.
A Wine Dark Sea: http://winedarksea.org/
A nice blog focussed on text mining, and visualisations.
Digital Scholarship in the Humanities: http://digitalscholarship.wordpress.com/
Lisa Shapiro’s blog, full of discussion about how to get started with Digital projects; and some of the issues involved.
History Carnival: http://historycarnival.org/
Monthly collection of history blogs, innovatively 'curated' by a different scholar each time, so each 'carnival' has a different focus and flavour.
Active History: http://activehistory.ca/
A Canadian blog and resource site that is focussed on public history and digital delivery.
Sapping Attention: http://sappingattention.blogspot.com/
A blog by Ben Schmidt from Princeton, reflecting his exploration of text mining techniques for the analysis of ‘big data’ (such as Google books).
Melissa Terras's blog: http://melissaterras.blogspot.co.uk/
A blog by the Professor of Digital Humanities, UCL
History Experiments: http://devonelliott.blogspot.com/2007/10/wikiarchives.html
A blog about dealing with historical data on line, written by Devon Elliott.
Philosophi.ca: http://www.philosophi.ca/pmwiki.php
Geoffrey Rockwell’s blog on digital humanities policies and debates. Full of up to date and prescient discussion.
Going Digital: http://williamjturkel.net/2011/03/15/going-digital/
William Turkel’s challenging guide to moving from analogue to digital historical research.
Digital Victorianist: http://www.digitalvictorianist.com/
Bob Nicholson's blog about digital research into the Victorian age. Particularly good on reviewing online newspaper databases.
Task 1: On your blog, compare and contrast the style, purpose, and features of at least THREE of the blogs listed above. Who is/are their author(s)? What topics do they discuss? How do they disseminate their research?
Further reading:
Amber Regis, 'Early Career Victorianists and Social Media: Impact, Audience and Online Identities', Journal of Victorian Culture, 17: 3 (2012)
Rohan Maitzen, 'Scholarship 2.0: Blogging and/as Academic Practice', Journal of Victorian Culture, 17: 3 (2012)
Week 4: xml and data mining
Reading 1: John Bohannon, 'Google opens books to new cultural studies', Science, 330: 6011 (15 Dec. 2010)
AND
Reading 2: Tim Hitchcock's blog, Historyonics, keynote lecture on 'Big Data for Dead People', http://historyonics.blogspot.co.uk/2013/12/big-data-for-dead-people-digital.html
- what is 'distant reading'?
- what is 'big data'?
- how does Hitchcock use xml to add further layers of historical analysis to the history of Sarah Durrant?
Further reading:
Jean-Baptiste Michel, Erez Lieverman Aiden, et al, 'Quantitative Analysis of Culture Using Millions of Digitized Books’, Science, 330: 6014 (16 Dec. 2010)
http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/
In the workshop we will do the following:
Task 1: Explore the possibilities of the large sets of data offered by these sites:
Task 2:
In the workshop we will be turning this piece of text into xml. The word document of the text, and a table to fill in, are attached below.
The Sydney Morning Herald (NSW : 1842 - 1954), Friday, 24 January 1890, p. 7. : http://trove.nla.gov.au/ndp/del/article/13757043
INQUEST.
An inquest was held yesterday morning by Mr. J. C. Woore, City Coroner, at the court, Chancery-square, on the body of James Ward, a labourer by occupation, and, 22 years of age. Deceased was single, and resided at Murray-street, Pyrmont. Thos. Quinn, quarryman, deposed that Ward and himself were working together at a quarry at the Darling Harbour railway, on Wednesday, and were in the act of raising a stone with an iron crowbar, when suddenly a large lump of stone, weighing about 841b., fell from the top, striking deceased, who bled freely from the ears; he was conscious, and was removed to the hospital, where he died at 7 o'clock. Other evidence was of a corroborative character. Dr. Wade stated that death was due to a fracture of the skull. The jury returned a verdict of accidental death.
Reading 1: John Bohannon, 'Google opens books to new cultural studies', Science, 330: 6011 (15 Dec. 2010)
AND
Reading 2: Tim Hitchcock's blog, Historyonics, keynote lecture on 'Big Data for Dead People', http://historyonics.blogspot.co.uk/2013/12/big-data-for-dead-people-digital.html
- what is 'distant reading'?
- what is 'big data'?
- how does Hitchcock use xml to add further layers of historical analysis to the history of Sarah Durrant?
Further reading:
Jean-Baptiste Michel, Erez Lieverman Aiden, et al, 'Quantitative Analysis of Culture Using Millions of Digitized Books’, Science, 330: 6014 (16 Dec. 2010)
http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/
In the workshop we will do the following:
Task 1: Explore the possibilities of the large sets of data offered by these sites:
- Old Bailey Online: http://www.oldbaileyonline.org/
- Mining the Dispatch: http://dsl.richmond.edu/dispatch/pages/intro
- Connected Histories: http://www.connectedhistories.org/Default.aspx
- Nines: http://www.nines.org/
- Google Ngram Viewer: http://books.google.com/ngrams
Task 2:
In the workshop we will be turning this piece of text into xml. The word document of the text, and a table to fill in, are attached below.
The Sydney Morning Herald (NSW : 1842 - 1954), Friday, 24 January 1890, p. 7. : http://trove.nla.gov.au/ndp/del/article/13757043
INQUEST.
An inquest was held yesterday morning by Mr. J. C. Woore, City Coroner, at the court, Chancery-square, on the body of James Ward, a labourer by occupation, and, 22 years of age. Deceased was single, and resided at Murray-street, Pyrmont. Thos. Quinn, quarryman, deposed that Ward and himself were working together at a quarry at the Darling Harbour railway, on Wednesday, and were in the act of raising a stone with an iron crowbar, when suddenly a large lump of stone, weighing about 841b., fell from the top, striking deceased, who bled freely from the ears; he was conscious, and was removed to the hospital, where he died at 7 o'clock. Other evidence was of a corroborative character. Dr. Wade stated that death was due to a fracture of the skull. The jury returned a verdict of accidental death.
| source_exercise_for_week_4_xml.docx |
| xmlworksheet.docx |
| dhlecture4xml.pptx |
| dhworkshop4notesxml.pdf |
week 5: visualisations
reading 1:
Watch: http://www.gapminder.org/videos/200-years-that-changed-the-world-bbc/
All visualisations on the web were essentially revolutionised in 2003 by Hans Rosling and Gapminder – a 5 minute video.
Reading 2: Have a play around with google ngram viewer: https://books.google.com/ngrams/
Then read Danny Sullivan, 'When OCR goes wrong': http://searchengineland.com/when-ocr-goes-bad-googles-ngram-viewer-the-f-word-59181
[see also Dan Cohen's take on it: http://www.dancohen.org/2010/12/19/initial-thoughts-on-the-google-books-ngram-viewer-and-datasets/]
Reading 3: Choose one of the visualisations on http://www.stanford.edu/group/spatialhistory/cgi-bin/site/gallery.php Answer the questions below on the discussion board and/or twitter.
There are several questions you want to ask yourself about any visualisation:
In the workshop we will be working our way through the following sites. The idea of this section is for us to go to a specific website, and work together to read it, in order to find out what makes it tick. One or two people will be asked to look up jargon and acronyms as we work through one or more of the sites below.
Comédie-Française Register Project: http://web.mit.edu/hyperstudio/cfr/index.html - An interesting implementation of ‘faceted’ browsing.
Cambridge Digital Library: http://cudl.lib.cam.ac.uk/collections/newton - The Newton Papers.
The Clergy of the Church of England Database: http://www.theclergydatabase.org.uk/index.html - An interesting database approach to organising information.
The Real Face of White Australia: http://invisibleaustralians.org/faces/ - A beautifully realised browser for images and text.
Transcribe Bentham: http://www.ucl.ac.uk/transcribe-bentham/ - UCL’s attempt to create a crowd sourced historical transcription project.
Spatial History Project: http://www.stanford.edu/group/spatialhistory/cgi-bin/site/gallery.php - a collection of visualisations of historical spatial data by Stanford University
New York Public Library Labs: Map Warper: http://maps.nypl.org/warper/ - An innovative group based in the New York Public Library - see their Map Warper in particular.
London Lives, 1690-1800: http://www.londonlives.org - An unusual attempt to digitise large numbers of manuscripts, with some crowdsourcing of biographies.
Connected Histories: http://www.connectedhistories.org/Default.aspx - Access to 10 billion words of material relating to British History.
Electronic Enlightenment: http://www.e-enlightenment.com/ - Digitised letters – see the innovative visualisation at Mapping the Republic of Letters: https://republicofletters.stanford.edu/
Nines: http://www.nines.org/ - A 'Federated Search' facility concentrating on 19th century resources.
Google Ngram Viewer: http://books.google.com/ngrams
HistoryPin: http://www.historypin.com/ - A project to crowdsource photographs and make them accessible via a google maps container.
StreetMuseum: http://www.museumoflondon.org.uk/Resources/app/you-are-here-app/index.html - A mobile App for viewing photographs in association with their location, created by the Museum of London.
Trove: http://trove.nla.gov.au/ - Nineteenth-century Australian newspapers – the most successful attempt to use crowdsourcing to correct OCR text.
Convict Transportation Registers Database: http://www.slq.qld.gov.au/info/fh/convicts - A database site, reflecting a structured approach to large scale data.
Henry III Fine Rolls Project: http://www.slq.qld.gov.au/info/fh/convicts - A large British site, representing a strong intellectual agenda and commitment to access.
reading 1:
Watch: http://www.gapminder.org/videos/200-years-that-changed-the-world-bbc/
All visualisations on the web were essentially revolutionised in 2003 by Hans Rosling and Gapminder – a 5 minute video.
Reading 2: Have a play around with google ngram viewer: https://books.google.com/ngrams/
Then read Danny Sullivan, 'When OCR goes wrong': http://searchengineland.com/when-ocr-goes-bad-googles-ngram-viewer-the-f-word-59181
[see also Dan Cohen's take on it: http://www.dancohen.org/2010/12/19/initial-thoughts-on-the-google-books-ngram-viewer-and-datasets/]
Reading 3: Choose one of the visualisations on http://www.stanford.edu/group/spatialhistory/cgi-bin/site/gallery.php Answer the questions below on the discussion board and/or twitter.
There are several questions you want to ask yourself about any visualisation:
- Can you interpret it?
- What do the makers aim to do?
- What sources does it use?
- Does it actually add any information?
- Can you manipulate it?
- Is it visually appealing?
In the workshop we will be working our way through the following sites. The idea of this section is for us to go to a specific website, and work together to read it, in order to find out what makes it tick. One or two people will be asked to look up jargon and acronyms as we work through one or more of the sites below.
Comédie-Française Register Project: http://web.mit.edu/hyperstudio/cfr/index.html - An interesting implementation of ‘faceted’ browsing.
Cambridge Digital Library: http://cudl.lib.cam.ac.uk/collections/newton - The Newton Papers.
The Clergy of the Church of England Database: http://www.theclergydatabase.org.uk/index.html - An interesting database approach to organising information.
The Real Face of White Australia: http://invisibleaustralians.org/faces/ - A beautifully realised browser for images and text.
Transcribe Bentham: http://www.ucl.ac.uk/transcribe-bentham/ - UCL’s attempt to create a crowd sourced historical transcription project.
Spatial History Project: http://www.stanford.edu/group/spatialhistory/cgi-bin/site/gallery.php - a collection of visualisations of historical spatial data by Stanford University
New York Public Library Labs: Map Warper: http://maps.nypl.org/warper/ - An innovative group based in the New York Public Library - see their Map Warper in particular.
London Lives, 1690-1800: http://www.londonlives.org - An unusual attempt to digitise large numbers of manuscripts, with some crowdsourcing of biographies.
Connected Histories: http://www.connectedhistories.org/Default.aspx - Access to 10 billion words of material relating to British History.
Electronic Enlightenment: http://www.e-enlightenment.com/ - Digitised letters – see the innovative visualisation at Mapping the Republic of Letters: https://republicofletters.stanford.edu/
Nines: http://www.nines.org/ - A 'Federated Search' facility concentrating on 19th century resources.
Google Ngram Viewer: http://books.google.com/ngrams
HistoryPin: http://www.historypin.com/ - A project to crowdsource photographs and make them accessible via a google maps container.
StreetMuseum: http://www.museumoflondon.org.uk/Resources/app/you-are-here-app/index.html - A mobile App for viewing photographs in association with their location, created by the Museum of London.
Trove: http://trove.nla.gov.au/ - Nineteenth-century Australian newspapers – the most successful attempt to use crowdsourcing to correct OCR text.
Convict Transportation Registers Database: http://www.slq.qld.gov.au/info/fh/convicts - A database site, reflecting a structured approach to large scale data.
Henry III Fine Rolls Project: http://www.slq.qld.gov.au/info/fh/convicts - A large British site, representing a strong intellectual agenda and commitment to access.
| dhlecture5visual.pptx |
Week 6: images
Read: Cohen and Rosenszweig, Digital History, chapter, 'designing history for the web': images - http://chnm.gmu.edu/digitalhistory/designing/3.php
Prior to this session, please download Irfanview from: http://www.irfanview.com/ and explore some of the basic features – particular in the bottom half of the pull-down menu entitled ‘Image’.
During the workshop, we will be joined by David Graves of Luton Culture. He will be leading a hands on activity on digitising World War One postcards. It is therefore really important that you attend this session.
Further reading:
The British Library have just released thousands of images scanned from their books.
http://www.flickr.com/photos/britishlibrary
http://britishlibrary.typepad.co.uk/digital-scholarship/2013/12/a-million-first-steps.html
https://imagesonline.bl.uk/?service=page&action=show_home_page&language=en
The British Museum have had this facility for some years now:
http://www.britishmuseum.org/research/search_the_collection_database.aspx
There is actually a huge amount of historical illustration available. These are just a few – mainly because they are free, and have few restrictions on copyright:
The Database of Mid-Victorian Illustration: http://www.dmvi.org.uk/index.php
The Lewis Walpole Library: http://lwlimages.library.yale.edu/walpoleweb/default.asp
Wellcome Images: http://images.wellcome.ac.uk/
British Printed Images to 1700: http://www.bpi1700.org.uk/jsp/
Flickr: the Commons: http://www.flickr.com/commons/
Cartoons: http://www.cartoons.ac.uk/
The only problem with all of this is that it is almost impossible to search for images. What you are normally actually searching is the metadata associated with each image – and that is incredibly variable.
Finding Images and then analysing them.
The real problem is finding the things. Some innovative search methodologies for images include:
Multicolor Search Lab: http://labs.ideeinc.com/multicolr/
TinEye: http://www.tineye.com/
PicSearch: http://www.picsearch.co.uk/
Google Search by Drawing: http://search-by-drawing.franz-enzenhofer.com/
Google Advanced Image Search: http://images.google.com/advanced_image_search?hl=en
And for history specific images:
The National Archives Historic Photo finder: http://lwlimages.library.yale.edu/walpoleweb/default.asp
And then, analysing them. Here is a nice blog that attempts to use bitmap characteristics for analysis:
http://lab.softwarestudies.com/2011/08/style-space-how-to-compare-image-sets.html
Using a Google Image Search, find this image – to be supplied on the day - in the best version available on the web and save it either to your own computer or a public storage facility such as DropBox. You also need to locate the fullest body of metadata about the image. I would start (and perhaps end with):
Google Advanced Image Search: http://images.google.com/advanced_image_search?hl=en
Read: Cohen and Rosenszweig, Digital History, chapter, 'designing history for the web': images - http://chnm.gmu.edu/digitalhistory/designing/3.php
Prior to this session, please download Irfanview from: http://www.irfanview.com/ and explore some of the basic features – particular in the bottom half of the pull-down menu entitled ‘Image’.
During the workshop, we will be joined by David Graves of Luton Culture. He will be leading a hands on activity on digitising World War One postcards. It is therefore really important that you attend this session.
Further reading:
The British Library have just released thousands of images scanned from their books.
http://www.flickr.com/photos/britishlibrary
http://britishlibrary.typepad.co.uk/digital-scholarship/2013/12/a-million-first-steps.html
https://imagesonline.bl.uk/?service=page&action=show_home_page&language=en
The British Museum have had this facility for some years now:
http://www.britishmuseum.org/research/search_the_collection_database.aspx
There is actually a huge amount of historical illustration available. These are just a few – mainly because they are free, and have few restrictions on copyright:
The Database of Mid-Victorian Illustration: http://www.dmvi.org.uk/index.php
The Lewis Walpole Library: http://lwlimages.library.yale.edu/walpoleweb/default.asp
Wellcome Images: http://images.wellcome.ac.uk/
British Printed Images to 1700: http://www.bpi1700.org.uk/jsp/
Flickr: the Commons: http://www.flickr.com/commons/
Cartoons: http://www.cartoons.ac.uk/
The only problem with all of this is that it is almost impossible to search for images. What you are normally actually searching is the metadata associated with each image – and that is incredibly variable.
Finding Images and then analysing them.
The real problem is finding the things. Some innovative search methodologies for images include:
Multicolor Search Lab: http://labs.ideeinc.com/multicolr/
TinEye: http://www.tineye.com/
PicSearch: http://www.picsearch.co.uk/
Google Search by Drawing: http://search-by-drawing.franz-enzenhofer.com/
Google Advanced Image Search: http://images.google.com/advanced_image_search?hl=en
And for history specific images:
The National Archives Historic Photo finder: http://lwlimages.library.yale.edu/walpoleweb/default.asp
And then, analysing them. Here is a nice blog that attempts to use bitmap characteristics for analysis:
http://lab.softwarestudies.com/2011/08/style-space-how-to-compare-image-sets.html
Using a Google Image Search, find this image – to be supplied on the day - in the best version available on the web and save it either to your own computer or a public storage facility such as DropBox. You also need to locate the fullest body of metadata about the image. I would start (and perhaps end with):
Google Advanced Image Search: http://images.google.com/advanced_image_search?hl=en
| dhworkshop6notesimages.pdf |
Week 7: mapping and Geographic Information Systems
In preparation for the workshop, read:
1. Play around with layering maps on: http://urbhist.nls.uk/extmap/ Read the explanatory text at http://geo.nls.uk/urbhist/mapbuilder.html
- what are the possibilities for historical research of laying historic maps and data?
2. Play around with Locating London's Past: http://www.locatinglondon.org/ How can the historian map the data and what might it tell us?
Read the methodology for mapping Roque's map: http://www.locatinglondon.org/static/MappingMethodology.html
Further reading: Read Alexander von Lunen, History and GIS (2012, e-book available via voyager/studynet), chapter 1.2, 'GIS and History'.
What, according to von Lunen, are the problems with GIS for historians?
In the workshop we will be learning how to geo-reference a historic map, and layering it on google maps or google earth.
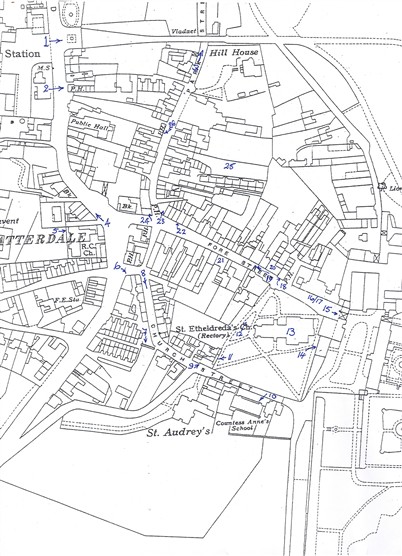
Task 1: set up an account with http://maps.nypl.org/warper/ and upload a historic map. You can use the 1937 OS map of old Hatfield on http://www.ourhatfield.org.uk/page_id__408_path__0p106p.aspx (attached below) or find your own. If you're really keen, register with Edina Digimap (via voyager/studynet) at least 24 hours in advance to access their historic OS map files.
Geo-reference your map following the instructions on the map warper.
Task 2: see how 'desifar you can get following the Programming Historian's lesson on mapping with google maps and google earth - http://programminghistorian.org/lessons/googlemaps-googleearth
In preparation for the workshop, read:
1. Play around with layering maps on: http://urbhist.nls.uk/extmap/ Read the explanatory text at http://geo.nls.uk/urbhist/mapbuilder.html
- what are the possibilities for historical research of laying historic maps and data?
2. Play around with Locating London's Past: http://www.locatinglondon.org/ How can the historian map the data and what might it tell us?
Read the methodology for mapping Roque's map: http://www.locatinglondon.org/static/MappingMethodology.html
Further reading: Read Alexander von Lunen, History and GIS (2012, e-book available via voyager/studynet), chapter 1.2, 'GIS and History'.
What, according to von Lunen, are the problems with GIS for historians?
In the workshop we will be learning how to geo-reference a historic map, and layering it on google maps or google earth.
Task 1: set up an account with http://maps.nypl.org/warper/ and upload a historic map. You can use the 1937 OS map of old Hatfield on http://www.ourhatfield.org.uk/page_id__408_path__0p106p.aspx (attached below) or find your own. If you're really keen, register with Edina Digimap (via voyager/studynet) at least 24 hours in advance to access their historic OS map files.
Geo-reference your map following the instructions on the map warper.
Task 2: see how 'desifar you can get following the Programming Historian's lesson on mapping with google maps and google earth - http://programminghistorian.org/lessons/googlemaps-googleearth
| hatfield1937.jpg |
| dhworkshop7gis.docx |
| postgraduate_history_training_session_6.docx |
Week 8: New model publishing and the open access debate
Workshop preparation:
Choose at least one of the following readings on the open access debate. Feel free to do your own research about it:
Discuss the question of open access, the Elsevier boycott, and the Finch report on the discussion board and twitter.
Should all research be open access? What sort of model should publishers and authors use ('green', 'gold')? What are the advantages and disadvantages for researchers? You should write at least two entries.
We will be doing a group exploration of the following two websites:
Founders and Survivors: Australian Life Courses in Context, 1803-1920: http://www.foundersandsurvivors.org/
A good example of a site focussed on public engagement.
Institute of Historical Research: http://www.history.ac.uk/
The focus of much development in Britain, with lots of sources, and some innovation.
Workshop preparation:
Choose at least one of the following readings on the open access debate. Feel free to do your own research about it:
Discuss the question of open access, the Elsevier boycott, and the Finch report on the discussion board and twitter.
Should all research be open access? What sort of model should publishers and authors use ('green', 'gold')? What are the advantages and disadvantages for researchers? You should write at least two entries.
- open access - http://blogs.lse.ac.uk/impactofsocialsciences/2012/07/02/strategy-wars-open-access/
- List of blogs and reports in reaction to the Finch Report: http://openaccess.blogs.sas.ac.uk/further-information/open-access-in-the-uk/
- Elsevier boycott - http://scholarlykitchen.sspnet.org/2012/02/02/mysteries-of-the-elsevier-boycott/
- Digital Victorianist blog post: 'Open Access: The $2,950 Book Review', http://www.digitalvictorianist.com/2013/06/open-access-book-revie/
- Melissa Terras's blog post: http://melissaterras.blogspot.co.uk/2013/11/im-not-going-to-edit-your-10000-pay-to.html
The debate from the American & South African point of view, with a useful graphic on publishing incomes: http://wiki.lib.sun.ac.za/images/e/ec/FRPAA-and-open-access.pdf
We will be doing a group exploration of the following two websites:
Founders and Survivors: Australian Life Courses in Context, 1803-1920: http://www.foundersandsurvivors.org/
A good example of a site focussed on public engagement.
Institute of Historical Research: http://www.history.ac.uk/
The focus of much development in Britain, with lots of sources, and some innovation.
| dhworkshop8notespublishing.pdf |
Week 9: Crowd Sourcing
Read: Cohen, Digital History, chapter, 'Collecting History Online', http://chnm.gmu.edu/digitalhistory/collecting/2.php
AND
Roy Rosenzweig, “Can History Be Open Source? Wikipedia and the Future of the Past', Journal of American History, (June 2006) - http://www.csupomona.edu/~zywang/Rosenzweig.pdf
[if you're interested in military history, also see Richard Jensen, 'Military History on the Electronic Frontier: Wikipedia Fights the War of 1812', Journal of Military History, 76 (Oct 2012) - http://www.americanhistoryprojects.com/downloads/JMH1812.PDF ]
In the workshop we will be doing a group exercise using Wikipedia. Register and make at least two revisions to a Wikipedia page. Come with a page and some revisions in mind. You will want to register with Wikipedia before the class.
Websites featuring crowd-sourcing:
Nigel Goose and the great Hertfordshire Census project:
http://www.herts.ac.uk/about-us/our-structure/subsidiary-companies/uh-press/history/hertfordshire-1851/census_cdrom.cfm
the Amazon Mechanical Turk:
https://requester.mturk.com/tour
https://requester.mturk.com/case_studies
But perhaps the most important example is Wikipedia
http://en.wikipedia.org/wiki/Main_Page
Two classic examples of very different approaches to historical materials are:
Trove:
http://trove.nla.gov.au/newspaper?q=
And Transcribe Bentham
http://www.transcribe-bentham.da.ulcc.ac.uk/td/Transcribe_Bentham
Feedback on blogs and assessments.
This will involve looking at each person’s blog, and their blog/submission for the first assignment. I realise that this a rather public exercise, and plan to approach it in a very non-judgemental way, but if you would prefer not to have your blog discussed by the group, please let me know in advance.
Read: Cohen, Digital History, chapter, 'Collecting History Online', http://chnm.gmu.edu/digitalhistory/collecting/2.php
AND
Roy Rosenzweig, “Can History Be Open Source? Wikipedia and the Future of the Past', Journal of American History, (June 2006) - http://www.csupomona.edu/~zywang/Rosenzweig.pdf
[if you're interested in military history, also see Richard Jensen, 'Military History on the Electronic Frontier: Wikipedia Fights the War of 1812', Journal of Military History, 76 (Oct 2012) - http://www.americanhistoryprojects.com/downloads/JMH1812.PDF ]
In the workshop we will be doing a group exercise using Wikipedia. Register and make at least two revisions to a Wikipedia page. Come with a page and some revisions in mind. You will want to register with Wikipedia before the class.
Websites featuring crowd-sourcing:
Nigel Goose and the great Hertfordshire Census project:
http://www.herts.ac.uk/about-us/our-structure/subsidiary-companies/uh-press/history/hertfordshire-1851/census_cdrom.cfm
the Amazon Mechanical Turk:
https://requester.mturk.com/tour
https://requester.mturk.com/case_studies
But perhaps the most important example is Wikipedia
http://en.wikipedia.org/wiki/Main_Page
Two classic examples of very different approaches to historical materials are:
Trove:
http://trove.nla.gov.au/newspaper?q=
And Transcribe Bentham
http://www.transcribe-bentham.da.ulcc.ac.uk/td/Transcribe_Bentham
Feedback on blogs and assessments.
This will involve looking at each person’s blog, and their blog/submission for the first assignment. I realise that this a rather public exercise, and plan to approach it in a very non-judgemental way, but if you would prefer not to have your blog discussed by the group, please let me know in advance.
Week 10: writing history on the web
Before the workshop:
1. Read: Cohen and Rosenzweig, Digital History, chapter 'building an audience', http://chnm.gmu.edu/digitalhistory/audience/
2. Prepare one page of historical material (perhaps based on your dissertation research?) to work into a history webpage during the workshop.
The sites we will be working through are not necessarily technically sophisticated, but they reflect strong historical content that has changed their corner of history. The point is to come to a conclusion about what makes good historical writing on the web.
1. The Workhouse –
http://www.workhouses.org.uk/
2. Rictor Norton’s site on Gay and Lesbian History:
http://rictornorton.co.uk/index.htm
3. the historical background pages of the London Lives website:
http://www.londonlives.org/static/Background.jsp
Designing a web architecture.
Please come prepared to outline a series of webpages containing information about a historical topic.
You can re-use an element of your other class work, or do something new. You don't need to prepare any writing, but you should have thought through the structured of a hierarchy of web pages, with links up and down the system. You should include a home page, index pages, a project page, etc., up to around 10 or 15 separate pages. Check out the ‘sitemap’ found on most good sites, for a sense of the number of pages that make up most historical resources.
This exercise can be undertaken either with pen and paper, using a package such as powerpoint, or word as a graphics editor, or else as a set of pages developed online in a free hosting context such as Weebly: see http://www.weebly.com/ (you can sign up for a free website using this facility).
Writing history for the web
Please bring enough information with you, to ensure you have some material to work with, and be prepared to develop it as a ‘draft’ blog page.
We will write up a single page of historical material in a format that is easy to read online - we can do this in your blogs, or in Weebly, or in Word. You should ensure that you keep sentences short, and paragraphs shorter. You should include subheadings, use images, links, navigation links, and an accessible style. You don’t have to publish it, if you don’t want to.
Extra reading:
The debate about 'long form' journalism - https://medium.com/journalism-deliberated/958f4e7691f5
http://www.marco.org/2014/01/26/long-form
Week 11: digital history projects from start to finish
This week we are looking at the stages of a digital history project from start to finish.
Read 1. Ben Schmidt’s most recent blog post on the problems with topic modelling:
http://sappingattention.blogspot.co.uk/2013/04/how-not-to-topic-model-introduction-for.html
And also, 2. Adam Crymble’s recent blog on crowdsourcing and correcting problems in online sources:
http://adamcrymble.blogspot.co.uk/2013/02/identifying-and-fixing-transcription.html
And look at the contents of the newest issue of Journal of Digital Humanities
http://journalofdigitalhumanities.org/
Skim read the project timeline and details of a funding bid by Tim Hitchcock for Locating London's Past in the pdf [on studynet]
- what types of issue does it cover?
- what different types of skill are needed to bring a digital project together?
This week we are looking at the stages of a digital history project from start to finish.
Read 1. Ben Schmidt’s most recent blog post on the problems with topic modelling:
http://sappingattention.blogspot.co.uk/2013/04/how-not-to-topic-model-introduction-for.html
And also, 2. Adam Crymble’s recent blog on crowdsourcing and correcting problems in online sources:
http://adamcrymble.blogspot.co.uk/2013/02/identifying-and-fixing-transcription.html
And look at the contents of the newest issue of Journal of Digital Humanities
http://journalofdigitalhumanities.org/
Skim read the project timeline and details of a funding bid by Tim Hitchcock for Locating London's Past in the pdf [on studynet]
- what types of issue does it cover?
- what different types of skill are needed to bring a digital project together?

{kind=link}